Configuring Quartz.net Cluster using SQL Azure and ASP.NET
It's hard to schedule tasks on Azure: The platform doesn't have built-in support for executing custom code based on a schedule. There's some options to get around this though, for example:
- Azure VM and the Windows Task Scheduler
- Azure Service Bus and ScheduledEnqueueTimeUTC
But these have some limitations which may be hard to get around: In the case of a VM, if it goes down, everything stops. With Azure Service Bus you need some service which handles the scheduling.
This is where the Quartz.net fits in. Quartz.net is a flexible and easy-to-use library for running scheduled tasks. And it works great on Azure.
Here's some highlights of Quartz.net's features:
- Supports clusters
- Can use SQL Azure
- Cron-style syntax for scheduling tasks
In this tutorial we build a Quartz.net (version 2.0.1) cluster using SQL Azure and ASP.NET.
The database
First we need to set-up the SQL Azure database. Quartz.net will persist all the job details and triggers to this database. Easiest way to create the required tables is to use Management Studio to log in to the database and to execute the Quartz.net database schema creation script.
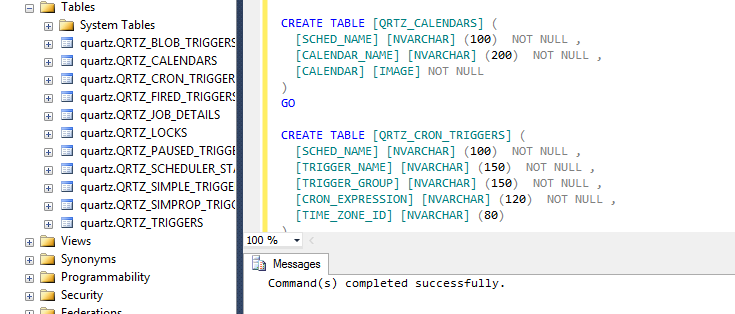
And that's it for the database. Next step is to build the service for running the Quartz.net.
The ASP.NET project
The SQL Azure store is ready and now we need a service which will run actions based on the triggers. The service can be almost anything: a console app, a Windows Service or an ASP.NET project. In this tutorial we're going to use an ASP.NET project which is deployed to two extra small Cloud Service instances.
Here are the steps required for creating the service:
- Create new project with template "ASP.NET Empty Web Application"
- Use NuGet to install package "Quartz"
- Add New Item to project using template "Global Application Class" (global.asax)
Modify the Global.asax.cs so that the Quartz.net starts and stop with the application:
using System;
using Common.Logging;
using Quartz;
using Quartz.Impl;
namespace QuarzApp
{
public class Global : System.Web.HttpApplication
{
public static IScheduler Scheduler;
protected void Application_Start(object sender, EventArgs e)
{
ISchedulerFactory sf = new StdSchedulerFactory();
Scheduler = sf.GetScheduler();
Scheduler.Start();
}
protected void Application_End(object sender, EventArgs e)
{
Scheduler.Shutdown();
}
}
}And finally modify the Web.config to include the Quartz.net configuration:
<?xml version="1.0"?>
<configuration>
<configSections>
<section name="quartz" type="System.Configuration.NameValueSectionHandler, System, Version=1.0.5000.0,Culture=neutral, PublicKeyToken=b77a5c561934e089" />
<sectionGroup name="common">
<section name="logging" type="Common.Logging.ConfigurationSectionHandler, Common.Logging"/>
</sectionGroup>
</configSections>
<system.web>
<compilation debug="true" targetFramework="4.5" />
<httpRuntime targetFramework="4.5" />
</system.web>
<common>
<logging>
<factoryAdapter type="Common.Logging.Simple.TraceLoggerFactoryAdapter, Common.Logging">
<arg key="showLogName" value="true"/>
<arg key="showDataTime" value="true"/>
<arg key="level" value="INFO"/>
<arg key="dateTimeFormat" value="HH:mm:ss:fff"/>
</factoryAdapter>
</logging>
</common>
<quartz>
<add key="quartz.scheduler.instanceName" value="MyScheduler" />
<add key="quartz.scheduler.instanceId" value="AUTO" />
<add key="quartz.threadPool.type" value="Quartz.Simpl.SimpleThreadPool, Quartz" />
<add key="quartz.threadPool.threadCount" value="5" />
<add key="quartz.threadPool.threadPriority" value="Normal" />
<add key="quartz.jobStore.useProperties" value="true" />
<add key="quartz.jobStore.clustered" value="true" />
<add key="quartz.jobStore.misfireThreshold" value="60000" />
<add key="quartz.jobStore.type" value="Quartz.Impl.AdoJobStore.JobStoreTX, Quartz" />
<add key="quartz.jobStore.tablePrefix" value="QRTZ_" />
<add key="quartz.jobStore.driverDelegateType" value="Quartz.Impl.AdoJobStore.SqlServerDelegate, Quartz" />
<add key="quartz.jobStore.dataSource" value="myDS" />
<add key="quartz.dataSource.myDS.connectionString" value="Server=tcp:myserver.database.windows.net,1433;Database=mydatabase;User ID=myuser@myserver;Password=mypassword;Trusted_Connection=False;Encrypt=True;Connection Timeout=30;" />
<add key="quartz.dataSource.myDS.provider" value="SqlServer-20" />
</quartz>
</configuration>That's it. The service for running the scheduled jobs is ready. As the last step we're going to create a simple job and a schedule for it.
Example job
All the bits and pieces are ready and only thing left is to test out the service. For that we need a job to execute and a trigger which will handle the execution.
The Quartz.net jobs implement a simple IJob interface. The following job will log a message when it is executed:
public class MyJob : IJob
{
private static ILog logging = LogManager.GetLogger(typeof (MyJob));
public void Execute(IJobExecutionContext context)
{
var mydata = context.MergedJobDataMap["data"];
logging.InfoFormat("Hello from job {0}", mydata);
}
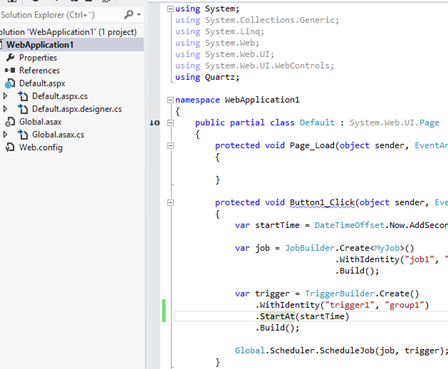
}To execute a job we need a trigger for it. Here's an example code which will add a single trigger for the job, making it to execute after 15 seconds has passed. Create a Web Form "Default.aspx" to the project, add a button to it and in its click handler create a new trigger and add it to the scheduler:
protected void Button1_Click(object sender, EventArgs e)
{
var startTime = DateTimeOffset.Now.AddSeconds(15);
var job = JobBuilder.Create<MyJob>()
.WithIdentity("job1", "group1")
.Build();
var trigger = TriggerBuilder.Create()
.WithIdentity("trigger1", "group1")
.StartAt(startTime)
.Build();
Global.Scheduler.ScheduleJob(job, trigger);
}Deployment and application pools
As the service uses ASP.NET, it can be deployed to Azure Web Sites or to Azure Cloud Services. One thing to keep in mind is that the IIS will recycle the application pools automatically. This will shut down the application and the Quartz.net with it. To get around this limitation, it may be wise to change the application pool's recycling interval to 0.
Another option is to create Quarz.net job which "pings" the current web site once in every 10 minutes or to use some other keep-alive service for the pinging.

























